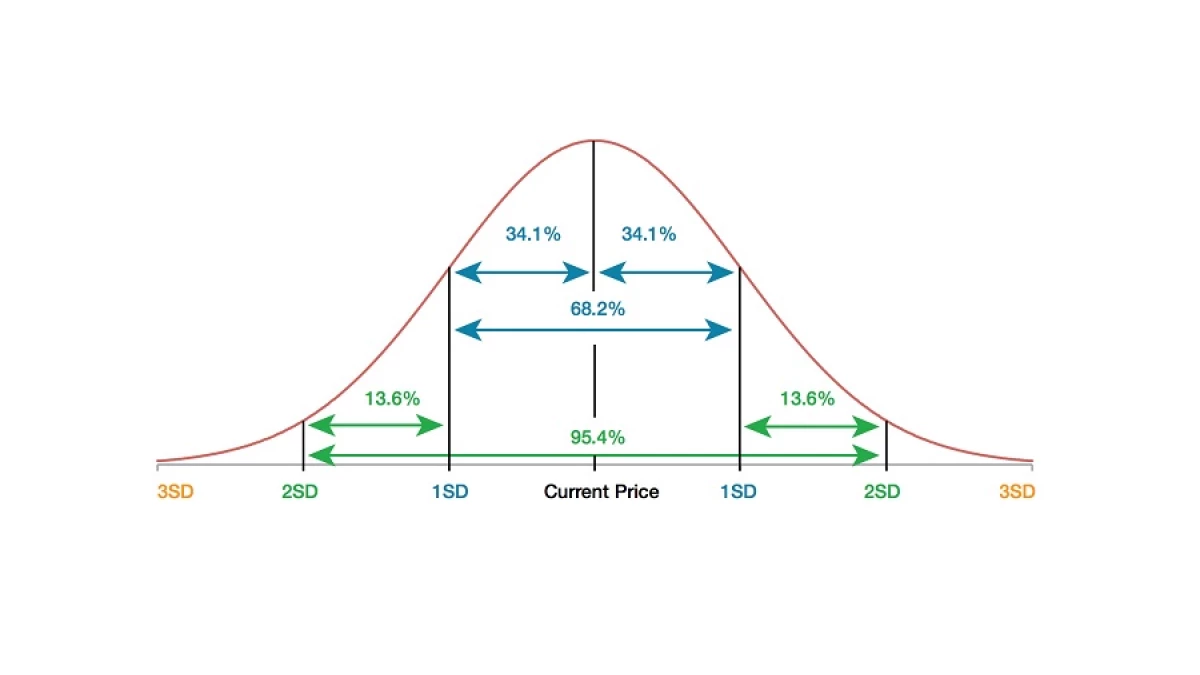

El término desviación típica o desviación estándar hace referencia a una medida que se utiliza para cuantificar la variación o la dispersión de datos numéricos en una variable aleatoria, población estadística, conjunto de datos o distribución de una probabilidad.
El mundo de la investigación y la estadística pueden parecer complejos y foráneos para la población general, pues parece que los cálculos matemáticos suceden bajo nuestra mirada sin que podamos entender los mecanismos subyacentes de los mismos. Nada más lejos de la realidad.
En esta oportunidad vamos a relatar de una forma sencilla pero a la vez exhaustiva el contexto, el fundamento y la aplicación de un término tan esencial como es la desviación típica en el ámbito de la estadística.
- Artículo relacionado: "Psicología y estadística: la importancia de las probabilidades en la ciencia de la conducta"
¿Qué es la desviación típica?
La estadística es una rama de las matemáticas que se encarga de registrar la variabilidad, así como el proceso aleatorio que la genera siguiendo las leyes de la probabilidad. Esto se dice pronto, pero dentro de los procesos estadísticos se encuentran las respuestas a todo lo que hoy consideramos como “dogmas” en el mundo de la naturaleza y la física.
Por ejemplo, pongamos que al tirar una moneda tres veces al aire, dos de ellas salga cara y una cruz. Simple coincidencia, ¿verdad? En cambio, si lanzamos al aire la misma moneda 700 veces y 660 de ellas cae de cara, quizá es posible que exista un factor que propicie ese fenómeno más allá de la aleatoriedad (imaginemos, por ejemplo, que solo le da tiempo a dar un número limitado de vueltas en el aire, lo que hace que casi siempre caiga del mismo modo). Así pues, la observación de patrones más allá de la mera coincidencia nos impulsa a pensar los motivos subyacentes de la tendencia.
Lo que queremos evidenciar con este ejemplo tan rocambolesco, es que la estadística es una herramienta esencial para cualquier proceso científico, pues en base a ella somos capaces de distinguir realidades fruto del azar de los sucesos regidos por leyes naturales.
Así pues, podemos arrojar una definición precipitada de la desviación típica y decir que se trata de una medida estadística producto de la raíz cuadrada de su varianza. Esto es como empezar la casa por el tejado, pues para una persona que no se dedique enteramente al mundo de los números, esta definición y no saber nada acerca del término se diferencian en poco. Dediquemos entonces un momento a diseccionar el mundo de los patrones estadísticos básicos.
Las medidas de posición y de variabilidad
Las medidas de posición son indicadores usados para señalar qué porcentaje de datos dentro de una distribución de frecuencias superan estas expresiones, cuyo valor representa el valor del dato que se encuentra en el centro de la distribución de frecuencia. No desesperes, pues te las definimos de forma rápida:
- Media: El promedio numérico de la muestra.
- Mediana: representa el valor de la variable de posición central en un conjunto de datos ordenados.
De forma rudimentaria, podríamos decir que las medidas de posición están enfocadas en dividir el conjunto de datos en partes porcentuales iguales, es decir, “llegar a la mitad”.
Por otro lado, las medidas de variabilidad se encargan de determinar el grado de acercamiento o distanciamiento de los valores de una distribución frente a su promedio de localización (es decir, frente a la media). Estas son las siguientes:
- Rango: mide la amplitud de los datos, es decir, desde el valor mínimo al máximo.
- Varianza: la esperanza (media de la serie de datos) del cuadrado de la desviación de dicha variable respecto a su media.
- Desviación típica: índice numérico de la dispersión del conjunto de datos.
Desde luego, nos estamos moviendo en términos relativamente complejos para alguien que no se dedique en su totalidad al mundo de las matemáticas. No queremos entrar en otras medidas de variabilidad, pues con conocer que cuanto mayores sean los productos numéricos de estos parámetros, menos homogeneizado estará el conjunto de datos.
- Quizás te interese: "Psicometría: ¿qué es y de qué se encarga?"
“La media de lo atípico”
Una vez hemos cimentado el conocimiento de las medidas de variabilidad y su importancia frente al análisis de datos, es momento de volver a centrar nuestra atención en la desviación típica.
Sin entrar en conceptos complejos (y quizá pecando de sobresimplificar las cosas), podemos decir que esta medida es producto del cálculo de la media de los valores “atípicos”. Pongamos un ejemplo para aclarar esta definición:
Tenemos una muestra de seis perras gestantes de la misma raza y edad que acaban de dar a luz a sus camadas de cachorros de forma simultánea. Tres de ellas han parido a 2 cachorros cada una, mientras que otras tres han dado a luz a 4 cachorros por hembra. Naturalmente, el valor medio de descendencia es de 3 cachorros por hembra (la suma de todos los cachorros dividido por el total de hembras).
¿Cuál sería la desviación típica en este ejemplo? En primer lugar, tendríamos que restarle a los valores obtenidos la media y elevar esta cifra al cuadrado (pues no queremos números negativos), por ejemplo: 4-3=1 o 2-3= (-1, elevado al cuadrado, 1).
La varianza se calcularía como la media de las desviaciones respecto al valor medio (en este caso, 3). Aquí estaríamos ante la varianza, y por ello, hemos de realizar la raíz cuadrada de este valor para transformarlo en la misma escala numérica que la media. Tras esto sí que obtendríamos la desviación estándar.
Entonces, ¿cuál sería la desviación típica de nuestro ejemplo? Pues un cachorro. Se estima que la media de las camadas es de tres descendientes, pero se encuentra dentro de la normalidad que la madre dé a luz a un cachorro menos o a uno más por camada.
Quizá este ejemplo pudiera sonar un poco confuso en lo que a varianza y desviación se refiere (pues la raíz cuadrada de 1 es 1), pero si en el mismo la varianza fuera de 4, el resultado de la desviación típica sería de 2 (recordemos, su raíz cuadrada).
Lo que hemos querido evidenciar con este ejemplo es que la varianza y la desviación típica son medidas estadísticas que buscan obtener la media de los valores distintos al promedio. Recordemos: cuanto mayor es la desviación estándar, mayor es la dispersión de la población.
Recuperando el ejemplo anterior, si todas las perras son de la misma raza y tienen pesos similares, es normal que la desviación sea de un cachorro por camada. Pero por ejemplo, si cogemos un ratón y un elefante, está claro que la desviación en lo que al número de descendientes se refiere alcanzaría valores mucho mayores a uno. De nuevo, cuanto menos tengan en común los dos grupos muestrales, será de esperar que las desviaciones sean mayores.
Aún así, una cosa es clara: utilizando este parámetro estamos calculando la varianza en los datos de una muestra, pero ni mucho menos esto tiene por qué ser representativo de una población entera. En este ejemplo hemos cogido a seis perras, pero, ¿y si monitorizáramos a siete y la séptima tuviera una camada de 9 cachorros?
Desde luego, el patrón de la desviación cambiaría. Por este motivo, tener en cuenta el tamaño muestral es esencial a la hora de interpretar cualquier conjunto de datos. Cuantos más números individuales se recopilen y más veces se repita un experimento, más cerca estaremos de postular una verdad general.
Conclusiones
Como hemos podido observar, la desviación típica es una medida de dispersión de datos. Cuanto mayor sea la dispersión mayor será este valor, pues si estuviéramos ante un conjunto de resultados completamente homogéneos (es decir, que todos fueran iguales a la media), este parámetro sería igual a 0.
Este valor es de enorme importancia en la estadística, pues no todo se reduce en encontrar puentes comunes entre cifras y sucesos, sino que también es esencial registrar la variabilidad entre grupos muestrales para poder así plantearnos más preguntas y obtener más conocimiento a largo plazo.
Referencias bibliográficas:
- Calcular la desviación estándar paso a paso, khanacademy.org. Recogido a 29 de agosto en https://es.khanacademy.org/math/probability/data-distributions-a1/summarizing-spread-distributions/a/calculating-standard-deviation-step-by-step
- Jaime, S., & Vinicio, M. (1973). Probabilidad y estadística.
- Parra, J. M. (1995). Estadística descriptiva e inferencial I. Recuperado de: http://www. academia. edu/download/35987432/ESTADISTICA_DESCRIPTIVA_E_INFERENCIAL. pdf.
- Rendón-Macías, M. E., Villasís-Keeve, M. Á., & Miranda-Novales, M. G. (2016). Estadística descriptiva. Revista Alergia México, 63(4), 397-407.
- Ricardi, F. Q. (2011). Estadística aplicada a la investigación en salud. Obtenido de La prueba de Ji-Cuadrado: http://www. medwave. cl/link. cgi/Medwave/Series/MBE04/5266.