

Cuando investigamos en psicología, dentro de la estadística inferencial encontramos dos conceptos importantes: el error tipo I y error tipo II. Estos surgen cuando estamos realizando pruebas de hipótesis con una hipótesis nula y una hipótesis alternativa.
En este artículo veremos qué son exactamente, cuándo los cometemos, cómo los calculamos y cómo podemos reducirlos.
- Artículo relacionado: "Psicometría: estudiando la mente humana a través de datos"
Métodos de estimación de parámetros
La estadística inferencial se encarga de extraer o extrapolar conclusiones de una población, a partir de la información de una muestra. Es decir, nos permite describir ciertas variables que queremos estudiar, a nivel de poblaciones.
Dentro de ella, encontramos los métodos de estimación de parámetros, que tienen como objetivo proporcionar métodos que permitan determinar (con cierta precisión) el valor de los parámetros que queremos analizar, a partir de una muestra aleatoria de la población que estamos estudiando.
La estimación de parámetros puede ser de dos tipos: puntual (cuando se estima un único valor del parámetro desconocido) y por intervalos (cuando se establece un intervalo de confianza donde “caería” el parámetro desconocido). Es dentro de este segundo tipo, la estimación por intervalos, donde encontramos los conceptos que analizamos hoy: el error tipo I y error tipo II.
Error tipo I y error tipo II: ¿qué son?
El error tipo I y error tipo II son tipos de errores que podemos cometer cuando en una investigación estamos ante la formulación de hipótesis estadísticas (como la hipótesis nula o H0 y la hipótesis alternativa o H1). Es decir, cuando estamos realizando pruebas de hipótesis. Pero para entender estos conceptos, primero debemos contextualizar su uso en la estimación por intervalos.
Como hemos visto, la estimación por intervalos se basa en una región crítica a partir del parámetro de la hipótesis nula (H0) que planteamos, así como en el intervalo de confianza a partir del estimador de la muestra.
Es decir, el objetivo es establecer un intervalo matemático donde caería el parámetro que queremos estudiar. Para ello, se deben realizar una serie de pasos.
1. Formulación de hipótesis
El primer paso es formular la hipótesis nula y la hipótesis alternativa, lo que, como veremos, nos llevará a los conceptos de error tipo I y error tipo II.
1.1. Hipótesis nula (H0)
La hipótesis nula (H0) es la hipótesis que plantea el investigador, y que provisionalmente acepta como verdadera. Solo puede rechazarla mediante un proceso de falsación o refutación.
Normalmente, lo que se hace es plantear la ausencia de efecto o la ausencia de diferencias (por ejemplo, sería afirmar que: “No hay diferencias entre la terapia cognitiva y la terapia de conducta en el tratamiento de la ansiedad”).
1.2. Hipótesis alternativa (H1)
La hipótesis alternativa (H1), en cambio, es la aspirante a suplantar o reemplazar la hipótesis nula. Esta suele plantear que existen diferencias o efecto (por ejemplo, “Existen diferencias entre la terapia cognitiva y la terapia de conducta en el tratamiento de la ansiedad”).
- Quizás te interese: "Alfa de Cronbach (α): qué es y cómo se usa en estadística"
2. Determinación del nivel de significación o alfa (α)
El segundo paso dentro de la estimación por intervalos es determinar el nivel de significación o el nivel alfa (α). Este lo fija el investigador al inicio del proceso; se trata de la probabilidad máxima de error que aceptamos cometer al rechazar la hipótesis nula.
Suele tomar valores pequeños, tales como 0.001, 0,01 o 0,05. Es decir, sería el “tope” o error máximo que estamos dispuestos a cometer como investigadores. Cuando el nivel de significación vale 0,05 (5%), por ejemplo, el nivel de confianza es de 0.95 (95%), y los dos suman 1 (100%).
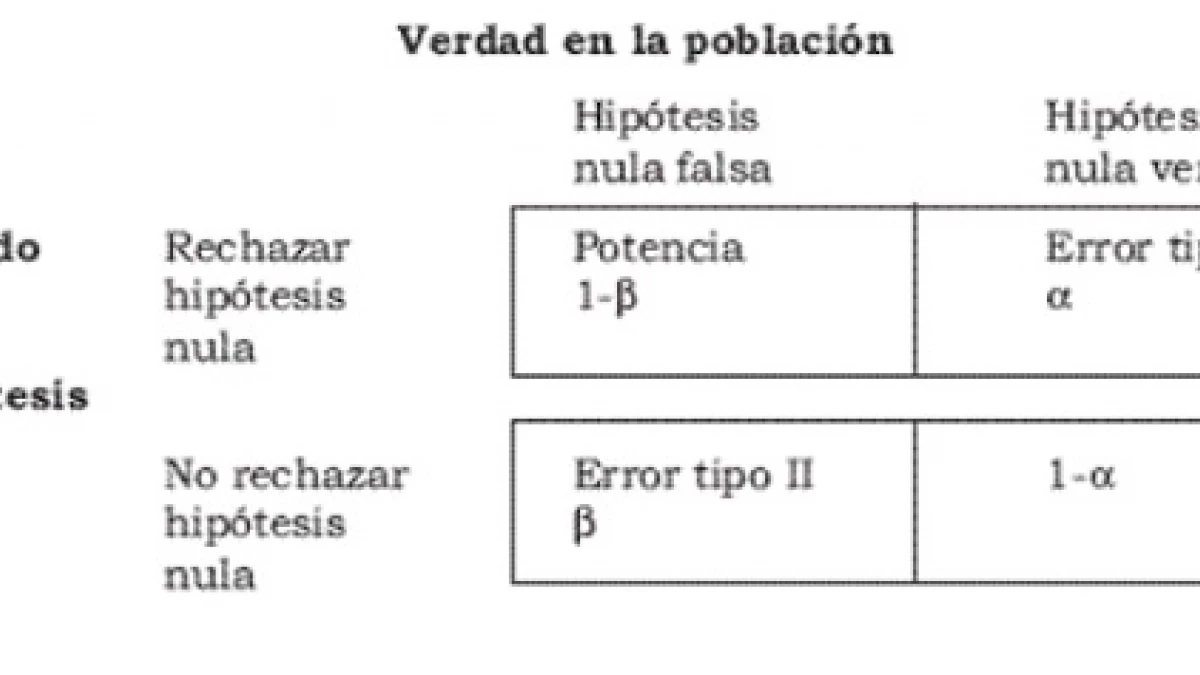
Una vez establecemos el nivel de significación, pueden ocurrir cuatro situaciones: que se produzcan dos tipos de errores (y aquí es donde entran el error tipo I y error tipo II), o bien que se produzcan dos tipos de decisiones correctas. Es decir, las cuatro posibilidades son:
2.1. Decisión correcta (1-α)
Consiste en aceptar la hipótesis nula (H0) siendo esta verdadera. Es decir, no la rechazamos, la mantenemos, porque es cierta. Matemáticamente se calcularía de la siguiente forma: 1-α (donde α es el error tipo I o nivel de significación).
2.2. Decisión correcta (1-β)
En este caso, también tomamos una decisión correcta; consiste en rechazar la hipótesis nula (H0) siendo esta falsa. También se llama potencia de la prueba. Se calcula: 1-β (donde β es el error tipo II).
2.3. Error tipo I (α)
El error tipo I, también llamado alfa (α), se comete al rechazar la hipótesis nula (H0) siendo esta verdadera. Así, la probabilidad de cometer un error de tipo I es α, que es el nivel de significación que hemos establecido para nuestra prueba de hipótesis.
Si por ejemplo el α que habíamos establecido es de 0.05, esto indicaría que estamos dispuestos a aceptar una probabilidad del 5% de equivocarnos al rechazar la hipótesis nula.
2.4. Error tipo II (β)
El error tipo II o beta (β), se comete al aceptar la hipótesis nula (H0) siendo esta falsa. Es decir, la probabilidad de cometer un error tipo II es beta (β), y depende de la potencia de la prueba (1-β).
Para reducir el riesgo de cometer un error tipo II, podemos optar por asegurarnos de que la prueba tiene suficiente potencia. Para ello, deberemos asegurarnos de que el tamaño de la muestra es lo suficientemente grande como para detectar una diferencia cuando ésta realmente exista.













